FogBugz is the easy-to-use software project management system for agile teams.
Why FogBugz?
- Out-of-the-box capabilities like time tracking, task management, bug & issue tracking and email support
- Support for multiple project management methodologies — such as Scrum, Kanban or Scrumban
- Nimble and customizable to match up with your workflows
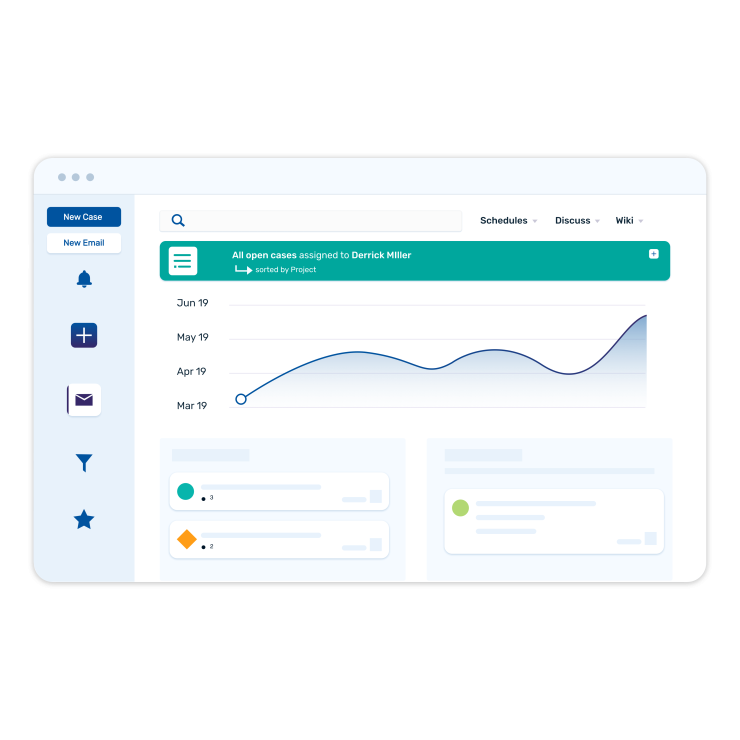
EVERYTHING YOU NEED IN ONE TOOL
FogBugz is designed for software development teams and includes all the project management tools developers need straight out of the box.
- Track projects from start to finish
You can create your tasks and subtasks for each case with required details and track them to ensure timely closure and accountability.
- Log and track all your bugs and issues
You can maintain your entire project backlog in FogBugz. Your team receives notifications as the bugs move through the workflow.
- Get accurate delivery estimates
FogBugz is powered by Evidence-Based Scheduling (EBS). EBS is a statistical algorithm that produces ship date probability distributions based on historical timesheet data.
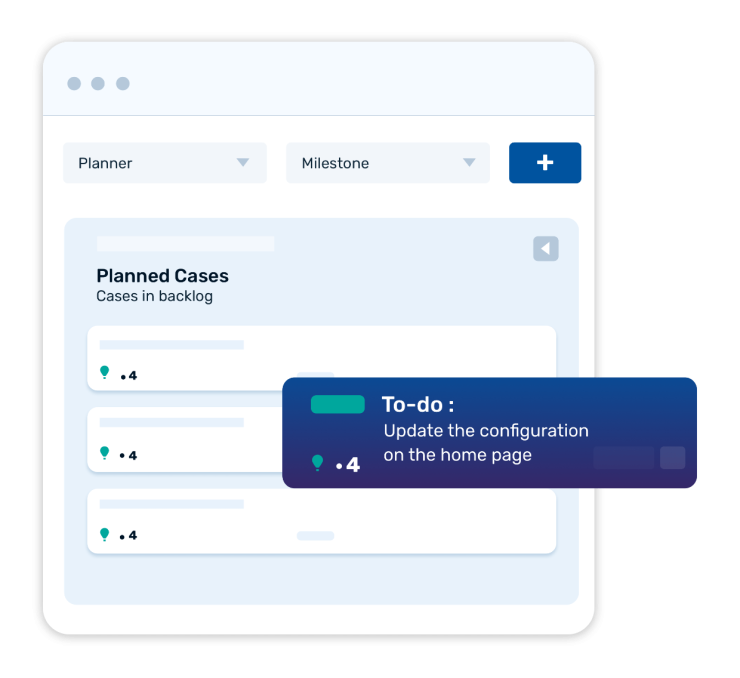
GET UP AND RUNNING IN NO TIME
FogBugz is fast and easy to use. It offers simple configuration and optimized workflows to jumpstart small teams.
- Track all cases in one place
FogBugz tracks bugs, issues and feature requests as cases in one place. Every case is prioritized and assigned to one person.
- Easily customize case flows
Use the workflows in FogBugz to match your team's needs. Plan at the project, sprint, epic, user story and task levels.
- Powerful search
Search docs, wikis, articles, code, issues, bugs and discussions in one unified view. Quickly find cases based on an array of case fields.
- Convenient integrations
Integrate FogBugz with Slack, Twitter, GitHub, Google Drive and Trello.


COMPLEMENTARY IGNITETECH UNLIMITED SOLUTIONS
Check out the solutions below, available free as part of your FogBugz subscription:
AlertFind
AlertFind
Enterprise notifications to communicate important information, monitor responses and verify staff safety.
Sococo
Sococo
Sococo is the online workplace where distributed teams come to work together each day, side-by-side.
Blog Posts

Jul 20, 2022
FogBugz and ScaleArc Transition to IgniteTech
IgniteTech today announced a transition of two software products from the ESW Capital portfolio to…

Jul 12, 2022
DNN Connect 2022: A trip report
Brad Mills, Chief Product Officer at IgniteTech, details his experience at the DNN Connect 2022…

Jul 1, 2022
The 3 Biggest Developments in Enterprise Cloud Today (and Why They're a Big Deal)
Get the top 3 developments in enterprise cloud and see how you can get updates on them for driving…

May 23, 2022
3 Things Enterprise Tech Leaders Need To Prioritize in 2022 and Beyond
To meet succeed in today’s turbulent business environment, enterprise tech leaders need to…

Jul 15, 2019
How Infobright's Columnar Database Supercharges Decision Making and Supports Organizational Agility
Enterprises are moving away from conventional OLTP relational databases in search of more convenient…

Mar 7, 2019
How an Event Data Warehouse Helps Meet Compliance Demands
Event data warehouse solutions are essential to meeting today’s compliance demands, helping…